——我国学者提出超越扩散模型的视觉自回归生成新范式
 打印
打印
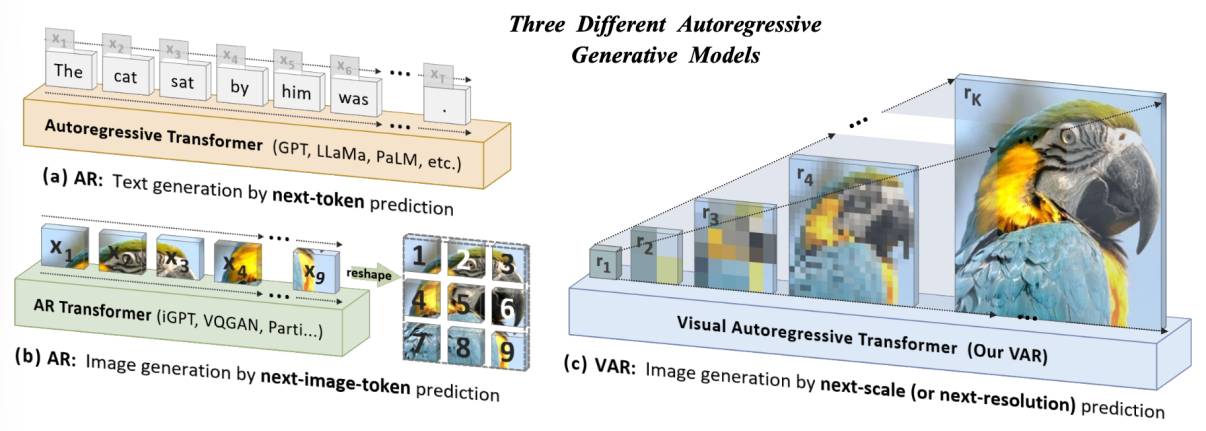
图 传统自回归建模与VAR视觉自回归建模的对比。(a)与(b)展示了传统方法机械地将图像视为一维序列,沿用类似于文本生成的“光栅扫描”顺序逐个预测Token;(c)展示了VAR提出的“Next-Scale预测”范式,模拟人类视觉认知规律,通过由粗到细的层级递进与尺度内并行生成,重构了图像生成的自回归逻辑,实现了效率与质量的双重突破
在国家自然科学基金项目(批准号:92470123、62276005)等资助下,北京大学王立威教授团队与合作者提出一套全新的视觉自回归生成范式VAR(Visual AutoRegressive Modeling),使得GPT风格的自回归视觉生成技术首次在效果、速度、Scaling能力方面超越Diffusion,迎来了视觉生成领域的Scaling Law。研究成果以“Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction”为题,于2024年12月10日在线发表于人工智能领域国际学术顶会NeurIPS(Neural Information Processing Systems),并被评选为“最佳论文奖”(Best Paper;从15671篇投稿中评选出2篇)。论文链接:https://proceedings.neurips.cc/paper_files/paper/2024/hash/9a24e284b187f662681440ba15c416fb-Abstract-Conference.html。
近年来,以GPT系列为代表的自回归(Autoregressive, AR)大语言模型通过“预测下一个词”的自监督学习策略,在自然语言处理领域展现了极强的通用智能与扩展能力。然而,在计算机视觉领域,尽管研究者尝试利用类似的自回归模型(如VQGAN、DALL-E等)进行图像生成,但其性能明显落后于扩散模型(Diffusion Models,如Stable Diffusion、SORA的基础架构DiT)。
针对传统视觉自回归模型因“光栅扫描”破坏图像二维结构且计算复杂度高的问题,研究团队提出了一种更符合人类视觉认知的“视觉自回归建模”(VAR)新范式,采用创新的“下一尺度预测”策略,通过由粗到细的层级生成过程,在大幅降低计算复杂度的同时保留了图像空间结构。实验显示,VAR在ImageNet基准上不仅以约20倍的推理速度大幅超越传统基线(FID从18.65优化至1.73),更在生成质量与数据效率上击败了当前最先进的扩散模型。该研究首次在视觉生成领域验证了与大语言模型一致的“缩放定律”(Scaling Laws)及零样本泛化能力,为构建统一的多模态通用人工智能架构提供了强有力的理论与实践支撑 。
