 打印
打印
在国家自然科学基金项目优秀青年科学基金等项目(批准号:62376013、623B2003、624B100026)资助下,北京大学人工智能研究院杨耀东助理教授指导博士研究生吉嘉铭和本科生邱天异在大模型后训练与对齐领域取得进展,相关成果以“Language Models Resist Alignment: Evidence From Data Compression”为题在自然语言处理领域顶级会议Association for Computational Linguistics(ACL) 2025中发表,并被评为最佳论文(Best Paper Award)。ACL 2025共收到投稿8000余篇,评选出四篇最佳论文,该工作是唯一由中国科研机构独立完成的获奖论文。
在人工智能对齐研究中,核心问题是让模型在理解指令的同时稳定地遵循人类价值与社会规范。然而,随着大模型规模与预训练数据量持续增长,后训练对齐能否保持长期稳定仍存在不确定性。
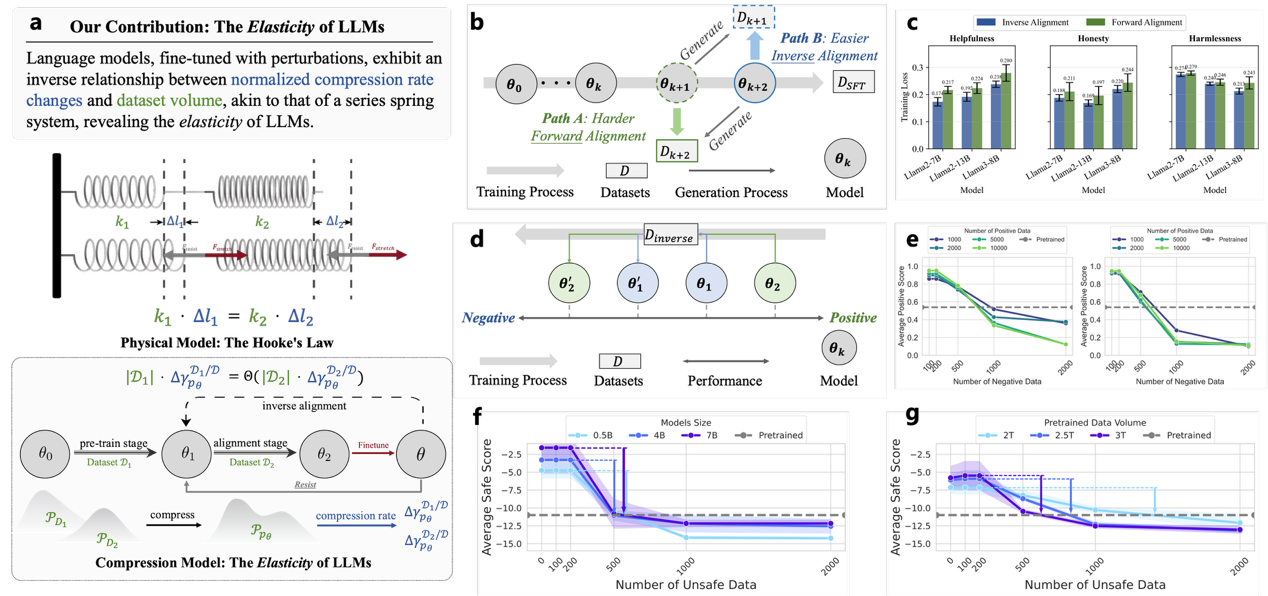
图 “语言模型弹性”框架及多尺度大模型实验验证
针对这一问题,项目团队从压缩理论视角提出“语言模型弹性”框架,发现对齐训练内在“抵抗对齐”现象。基于多尺度模型的理论建模与实验表明,对齐状态并非静态稳态,而近似“胡克定律”式的弹性形变,外部对齐约束存在时模型被拉升至合规区,约束撤除后则按预训练形成的原始平衡点回弹。此趋势在参数规模更大、预训练数据更多的模型上更为显著。对齐具有脆弱性与易逆性,在使用大量正向数据进行微调后,仅需数量级显著更小的反向样本即可明显削弱甚至抵消既有对齐效果;同时存在“欺骗性对齐”与“阿谀式响应”风险,即模型在监督在场时表现合规、监督缺位时违偏的人类偏好策略,并倾向迎合用户立场形成确认偏误闭环。
该研究获得审稿人及领域主席的高度认可,一致认为该研究提出的“弹性”概念突破性地揭示了大语言模型在对齐过程中的抵抗与回弹机制,为长期困扰该领域的“对齐脆弱性”问题提供了新的理论视角与坚实基础。领域主席则进一步指出,论文在压缩理论、模型扩展性与安全对齐之间搭建起桥梁,不仅实证扎实、理论深入,更具深远的治理和安全启发意义。
