——我国学者在大语言模型基础范式研究方向取得进展
 打印
打印
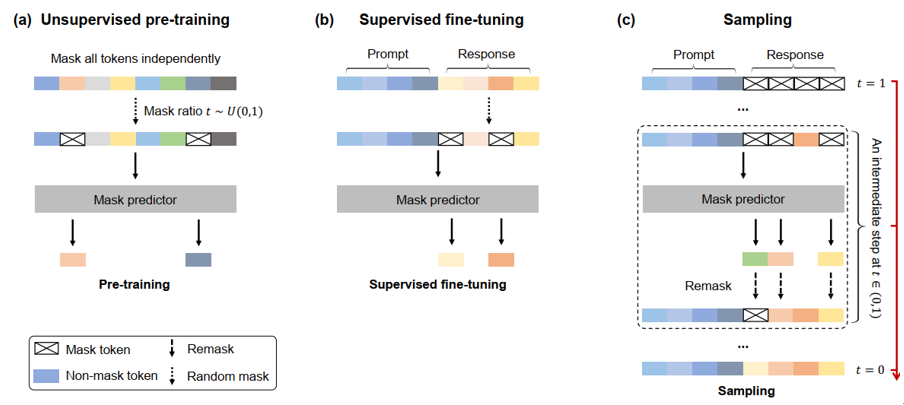
图 LLaDA的训练和推理原理示意图。
在国家自然科学基金项目(批准号:92470118)等支持下,中国人民大学高瓴人工智能学院李崇轩副教授、文继荣教授围绕大语言模型的基础建模范式开展系统研究,提出首个可对话的扩散大语言模型。研究成果以“大规模语言扩散模型(Large Language Diffusion Models)”为题,于2025年11月30日在线发表于国际学术会议《神经信息处理系统年会》(Annual Conference on Neural Information Processing Systems),入选大会口头报告,论文链接:https://neurips.cc/virtual/2025/loc/san-diego/poster/118608,并在Hugging Face平台(https://huggingface.co/GSAI-ML)开源,模型总下载量超350万次。该研究成果预印版在国际学术会议《国际表示学习大会》(International Conference on Learning Representations)生成模型研讨会获得唯一长文最佳论文奖(Long Paper Best Paper Award)。
大语言模型已成为对话机器人、代码生成、数学推理与智能体等应用的核心底座。长期以来,主流大语言模型采用自回归(Autoregressive)架构:从左到右逐词元串行生成文本。这一范式虽然日趋成熟,但存在几类结构性问题:(1)解码过程高度串行,推理延时高;(2)从左到右单向建模,忽略了语言中反向推理、上下文推敲等类型的统计规律;(3)依赖“思维链”等重新回答问题的方式修正之前答案中的错误,缺少内在纠错机制。因此,亟待探索大语言模型基础架构新范式,解决自回归模型的上述结构性问题。
该研究的主要洞见是:语言模型的核心在于逼近真实语言分布,而非绑定于自回归结构。基于此,该研究提出了扩散大语言模型 LLaDA(Large Language Diffusion with mAsking),把“逐词元续写”改为“基于双向上下文去掩码”的扩散过程:在保持大模型能力体系(上下文学习、指令遵循、多轮对话等)的同时,具备全局式建模、修改与并行生成的潜力。实验结果显示,在模型参数量和训练数据规模相当的条件下,LLaDA的性能可以媲美自回归模型,并在反向语言任务中超越同时期的GPT-4o等先进闭源大语言模型。
该研究提出了语言建模的新范式,为突破自回归推理瓶颈提供了极具前景的新路径;也挑战了“文字接龙”的领域共识,加深了对语言模型架构的理解;同时,提供了一种非序列化离散数据的通用建模方法,为面向多模态和科学数据的生成式建模提供了新工具。
