| |
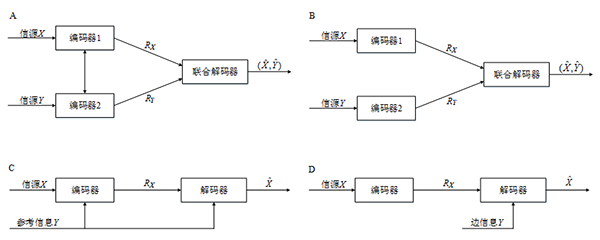 |
图1 传统信源编码和分布式信源编码原理对比示意图:(A)传统信源编码(对称式);(B)分布式信源编码(对称式);(C)传统信源编码(非对称);(D)分布式信源编码(非对称)
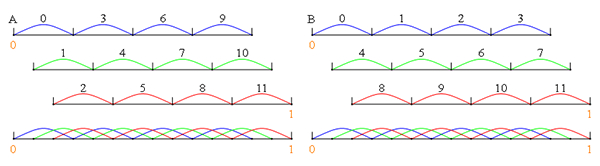
图2 多元分布式算术码的符号-区间映射规则示意图:(A)等距递增;(B)等距交错
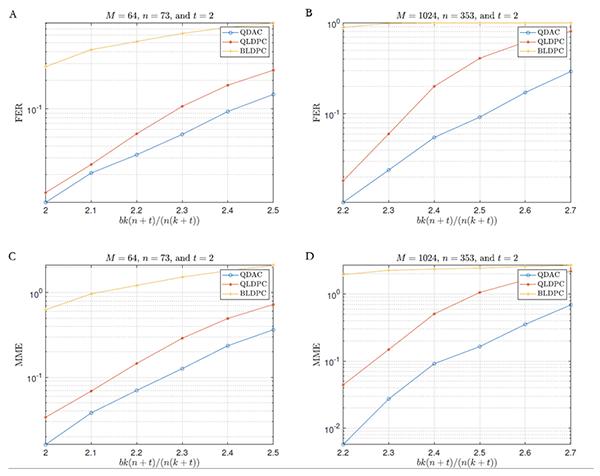
图3 1/2码率下不同码长多元分布式算术码与基于信道码(LDPC码)的分布式信源编码性能对比图(短码码长为75个256元符号,等效于600个比特;长码码长为355个256元符号,等效于2840个比特):(A)短码误帧率;(B)长码误帧率;(C)短码曼哈顿残差;(D)长码曼哈顿残差
在国家自然科学基金项目(批准号:62141101)资助下,长安大学方勇教授在分布式信源编码研究方面取得进展。研究成果以“多元等概信源的多元分布式算术码(Q-ary Distributed Arithmetic Coding for Uniform Q-ary Sources)”为题于2022年12月 22日发表在期刊《电气电子工程师协会·信息论汇刊》(IEEE Transactions on Information Theory)上。文章链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9944690。源码链接:https://github.com/fy79/Qary-DAC。
近年来,语音、图像、视频等各类数据呈爆炸式增长,为了消除这些数据的冗余度以提高通信有效性,信源编码技术根据信源符号序列的统计特性将其变换为尽可能短的码字序列,使编码后各码元所载荷的平均信息量最大,同时又能无失真(或以尽可能小的失真)来恢复原始符号序列。传统的集中式信源编码主要建立在单信源-单信宿的点到点信息论基础之上,致力于建立单个节点信源编码的率失真理论边界,以及探索可达到这些理论边界的实际编码方案。而在多个节点并存的智能交通稠密监控系统和居民基因数据库等实际应用场景中,多个节点的原始数据中具有很高的时空相关性,如果仍采用传统的集中式信源编码,各节点的信源编码器之间需通过互相通信来获取彼此的信息,存在编码器复杂度高、设备功耗大、布置成本高等问题。与传统的集中式编码方法相比,分布式信源编码方法能够对信息互相关联的多个节点进行独立的信源编码,而不需要节点之间的相互通信,进而在解码端以联合解码的方式恢复出多个节点的原始数据,将计算复杂度由编码端转移到解码端(服务器),从而很好地解决了传统集中式信源编码方法存在的问题(图1)。
由于相关信源之间的预测残差可以建模为虚拟信道的加性噪声,分布式信源编码在本质上等效于虚拟信道上的信道编码问题,因此现有分布式信源编码的实现方式通常基于各种信道码(如Turbo码、LDPC码和极化码)。基于信道码的分布式信源编码实现方式存在的主要问题在于模型失准:信道码通常基于加性白高斯噪声(AWGN)信道模型进行优化,因而在欧式距离的意义上是最优的;然而对于实际相关信源(例如视频信号)而言,其预测残差往往服从拉普拉斯分布,而不是高斯分布。此时,欧氏距离意义上的最优信道码无法同时满足曼哈顿距离意义上的最优,因此基于信道码的分布式信源编码实现方式无法达到Slepian-Wolf定理所给出的无损分布式信源编码的理论极限。
为了缩小现有基于信道码的分布式信源编码实现方式的实际性能与Slepian-Wolf定理的理论极限之间的差距,方勇教授研究了多元分布式算术码,其主要创新性思路在于直接以曼哈顿距离作为度量工具,设计了曼哈顿距离意义上的最优编解码方案。他从理论上严格证明了:随着分组长度趋于无穷大,每个分组的多元分布式算术码流的总码率损失趋于一个有限常数,因此单个符号的平均码率损失趋于零,亦即多元分布式算术码性能可以达到理论极限。多元分布式算术码的设计核心是符号-区间映射规则,为此他提出等距交错符号-区间映射规则(图2),根据曼哈顿距离进行陪集空间分割,解决了拉普拉斯相关信源的最优解码问题。在1/2码率情况下,当码长为75个256元符号(等效于600个比特)和355个256元符号(等效于2840个比特)时,多元分布式算术码的误帧率只有基于LDPC码的分布式信源编码实现方式的一半左右(图3A和3B),而在曼哈顿残差这一指标上多元分布式算术码的优势甚至更加显著(图3C和3D)。上述工作表明:多元分布式算术码解决了当前基于信道码的分布式信源编码实现方式无法达到理论极限的问题,是实现多个相关信源分布式编码的优良候选方案。
项目研究成果为有效降低多节点信源编码应用场景中的编码端算力需求提供了理论基础和新的解决思路。