在国家自然科学基金项目(批准号:61525306, 61633021, 61721004)资助下,中国科学院自动化研究所王亮研究团队在视觉-语言理解研究方面取得进展。最新研究成果以“基于对齐跨模态记忆的小样本图文匹配(Few-Shot Image and Sentence Matching via Aligned Cross-Modal Memory)”为题,于2021年1月18日在《IEEE模式分析与机器智能汇刊》(IEEE Transactions on Pattern Analysis and Machine Intelligence, IEEE TPAMI)上在线发表。论文链接:https://ieeexplore.ieee.org/document/9328198。
视觉-语言理解是当前计算机视觉领域的新兴研究问题之一,在传统视觉目标识别、检测与分割的基础上,侧重在高层语义上实现视觉和语言数据之间的关联、生成与问答等交互操作,可用于智能手机、视频网站、服务机器人等实际场景。该研究问题一经提出便吸引了大量计算机视觉、自然语言理解领域的研究人员,衍生出了图文匹配、视觉描述、视觉问答、视觉-语言导航等一些列具有较强技术挑战性和现实应用需求的任务(图1)。
该团队在研究传统视觉分析方法的基础上,在视觉语义内容提取与组织、视觉-语言小样本学习等方面取得了系列成果。通过将多标签分类器作为语义概念提取器,把全局视觉表示升级为局部语义概念表示,强化了视觉和语言在实例层面的相似性度量[IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2310-2318, 2017];通过整合全局上下文信息,实现了语义概念的顺序学习,进而产生正确的全局语义表示[CVPR, pp. 6163-6171, 2018];将局部语义概念表示和语义顺序学习放到一个统一框架下进行联合学习,验证了视觉语义内容选择性提取与序列化组织方式的有效性[IEEE TPAMI, 42(3): 636-650, 2020]。
在此基础上,该团队进一步研究了面向真实场景下的视觉-语言标注数据缺失问题,即小样本视觉-语言理解[AAAI Conference on Artificial Intelligence (AAAI), 8489-8496, 2019]。通过基于多模态预训练模型和类脑长时记忆机制建模[IEEE International Conference on Computer Vision (ICCV), 5774-5783, 2019],提出能够进行跨模态知识存储与复用的模型,验证了视觉-语言知识结构化表示和层次化组织的有效性,在图文匹配等任务上取得当时领先结果。
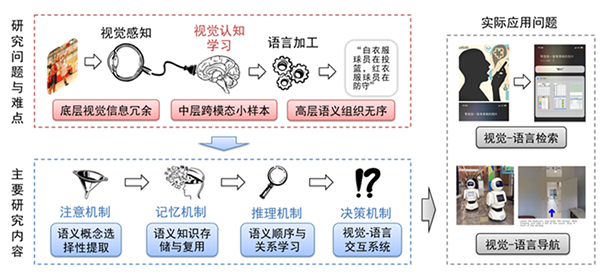
图1 视觉-语言理解示意图